Overview
The essence of the Digital Text Processing System e-magyar.hu is to automatically realise the basic, initial steps of text reception and comprehension – tasks requiring human intelligence: the linguistic characteristics of a text are automatically revealed and made explicit. Processing any given text means that each word is part-of-speech-tagged, lemmatised and is analysed morphologically, the sentences are analysed syntactically (yielding two analyses), furthermore the nominal phrases and named entities are marked, as well. The toolchain gathers, integrates and presents the respective NLP tools in a unified system, making them accessible and directly usable for user groups with different needs.
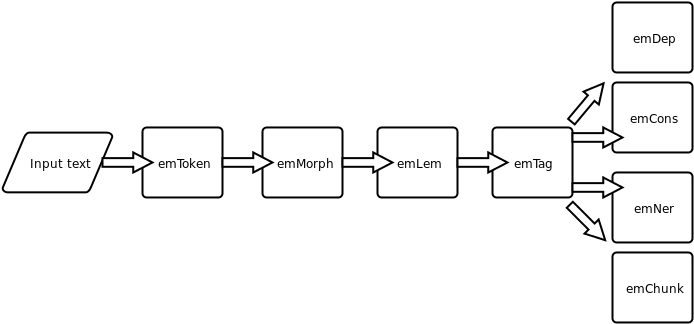
The text processing section of e-magyar.hu has the following modules:
- Tokeniser – emToken
- Morphological analyser – emMorph
- Word stemmer (Lemmatiser) – emLem
- POS Tagger – emTag
- Dependency parser – emDep
- Constituent parser – emCons
- NP Chunker (partial syntactic analyser) – emChunk
- NER Tagger – emNer
A description of the respective tools is available under their direct link.
Example
Bár külföldre menekülhetett volna, nem tette meg. Támogatta a haladó eszméket, barátságban állt pl. Jókai Mórral is.
When automatically processing the above text, the first step is to determine the sentence boundaries and to segment the text into so-called tokens: the basic units of the text, comprising of words and punctuation marks. In the above example Támogatta starts a new sentence, but Jókai does not, even though a period is followed by a word with an initial capital letter in both cases – which generally signals a sentence boundary. Punctuation marks are dealt with separately, except for when they occur as part of abbreviations, which include the period, as well. Accordingly, pl. will count as one unit, while is and the period following it will count as two units.
We also arrive at morphological information about each word form: menekülhetett is a verb in past tense, having menekül as a lemma, and -hat / -het as a suffix and -ett as verb ending.
The majority of Hungarian word forms (up to 30%) have multiple morphological analyses. In such cases the system automatically choses one of the possible alternatives, relying on the context. This step is called disambiguation. Ambiguity is not always as obvious as in the case of várnak or terem, in many cases it is quite hidden. It is important for example to analyse haladó as an adjective, and not as a compound noun referring to some kind of a tax related to fish.
The syntactic analysis of the sentences is carried out in two different ways. One is a so-called dependency parsing, which yields the relations of the words to each other (such as barátságban being an adverb related to the verb állt). The other syntactic analysis is called constituency parsing. This returns the constituents of the sentence; in the example above the sentence is made up of two larger units, which are coordinated. Thanks to the dependency parsing verb + prefix relations are also at our disposal. Using this information a separate module marks separable prefixes and their related verbs, in the example above: tette and meg.
Nominal phrases – such as haladó eszméket – are also identified by a specific module. .
The last module of the toolchain marks subclasses of propoer names, such as place- or organisation names, person names, such as Jókai Mór in our example.